
























Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
W ostatnich dniach spędzam dużo z mojego wolnego czasu w domowym zaciszu. Nie dlatego, że tak lubię, wręcz przeciwnie. W klimacie nadchodzącej wiosny, wolał bym ją witać osobiście (choć nie nie sam), z należnym jej ceremoniałem i na zewnątrz. Powody tej mojej wiosennej absencji są oczywiste, jak i mi, tak i wszystkim nam zdarza się to przeżywać w podobny sposób. A więc siedzę grzecznie w domu i wypełniam swój obywatelski i po prostu ludzki obowiązek. Siedzę i myślę. Nabieram dystansu do życia, które nazywam teraz tym poprzednim. Widzę je inaczej, bo z nieznacznego daleka, paradoksalnie widać więcej. Co widzę? Zdecydowanie to nie jest miejsce i czas aby o tym pisać, blog techniczny ma swoje wymagania, nawet w tak wyjątkowej sytuacji. Więc oszczędzę Wam. Jak się domyślacie nie było by tego wpisu gdyby nie istniało jakieś „ale” o którym jednak napisać postanowiłem.
Jak każdy, który ma to szczęście i przekleństwo zawodowo „robić” swoją pasję, w wolnym czasie lubię coś skrobnąć, dłubnąć. Szczególnie jak to jest coś, co będzie żyło, trafi na produkcję, do ludzi. W tym klimacie, przyszło mi w ostatnich dniach mocno odkurzyć mój SQL’owy warsztat. SQL, no cóż, moja pierwsza miłość. Kiedy się poznawaliśmy nie wiedziałem, że będzie to znajomość tak trwała i tak intensywna. Znajomość, która przetrwała wszystkie inne. SQL to jedyny język którego używam wciąż, nieprzerwanie od początku. Zmieniają się paradygmaty, platformy, architektury a on trwa. Mylą się Ci którzy myślą, że jest tak przez pewną formę „zasiedzenia”, że język ten po prostu się tak mocno rozpowszechnił, przekraczając masę krytyczną, że nie ma jak go szybko zastąpić czymś nowszym. Także mylnie interpretuje się ruch spod szyldu „NoSQL”. Ruch ten należy rozumieć raczej jako „nie tylko SQL”, co jest na tyle rozsądne, że nie sposób się z tym nie zgodzić. Moim zdaniem SQL jest popularny ze względu na swoje cechy, z których większość to trudno dyskutowalne zalety.
Pierwszą jest to, co stoi za językiem SQL, relacyjny, oparty na zbiorach model danych. Model taki wciąż dla wielu przypadków jest modelem zbliżonym do optymalnego.
Druga cecha to deklaratywność. Nie umiem sobie wyobrazić rozmiaru geniuszu który musiał nawiedzić twórców SQL, w chwili w której podejmowali decyzję o tym, że ten język ma być deklaratywny. Weźmy poprawkę na to, że działo się to ponad 40 lat temu. Dla mniej wtajemniczonych, wyjaśnię, że smutek języków imperatywnych polega na tym, że chcąc coś zaprogramować musimy powiedzieć
jak to ma być zrobione
a to zazwyczaj trudna i mozolna praca, obarczona ogromnym ryzykiem popełnienia błędów. W językach deklaratywnych natomiast, mówimy
co chcemy otrzymać
i o ile nie pomylimy się w wyrażeniu własnych potrzeb, to otrzymamy poprawny wynik. Uff, różnica jest ogromna.
Trzecią bardzo ważną cechą SQL jest jego prostota i silna analogia ze zwykłym językiem używanym na co dzień. Potrzebujesz wyciągnąć premie pracowników z listopada 2019? Proszę bardzo:
Select firstName, lastName, bonus from salary where month = 11 and year = 2019
czytelnie, pięknie, w ogóle nie technicznie, kompletnie nie informatycznie. Wspaniale. Czy na tym bożym świecie są ludzie którzy mają lepiej niż programiści SQL?
Drzewiej, za tak zwanego „pacana”, kiedy to człek był młody i nasz osławiony SQL także był taki, występowały jednak pewne problemy. Bo weźmy na przykład taką potrzebę: potrzebujesz wyciągnąć premie pracowników z listopada 2019, nie tylko ich wartości, ale w drugiej kolumnie także ich średnią wartość z ostatniego roku, do tego na liście muszą się znaleźć wyłącznie osoby które mają dzieci poniżej 8 roku życia, i nie były wysyłanie na kurs operatora koparki, w dodatku jak ktoś takiej premii nie miał to ma także znaleźć się na liście ale z kwotą zero. We wczesnych latach życia SQL’a mogły pojawić się problemy z realizacją takiego zadania. Zapytanie o dane musiało być wyrażone jednym zdaniem. Na szczęście do standardu SQL szybko dodano funkcjonalność podzapytań, a znacznie później „boskie” słowo (nie zawaham się tak powiedzieć)
with
With wprowadziło nas w świat konstrukcji dziwacznie zwanych CTE (common table expression), pomijając tą dziwaczną nazwę, konstrukcji niezmiernie przydatnych. With jednoznacznie i terminalnie sprawia że SQL jest językiem nie tylko realizacji pojedynczych zapytań o dane, ale także językiem historyjek złożonych z wielu zapytań następujących po sobie. CTE nas wyzwala. Już wiemy, że możemy wszystko. Nie ma takiej potrzeby której SQL’em z CTE nie jesteśmy w stanie zrealizować. Możemy teraz opowiedzieć, stworzyć wieloetapową historię, gdzie na etapach kolejnych mamy dostęp do wyników z etapów wcześniejszych, nagle pojawiają się nam w bazie tabele których nigdy nie było i to wszystko bez pisania procedur, tabel tymczasowych i skomplikowanego kodu. Podsumowując, SQL to potężne i wciąż niezastąpione narzędzie.
Jak na tym tle wypadają tytułowe Monady, porównane oczywiście z SQL? Zacznijmy od tego czym jest Monada. Jest to twór co najmniej dziwny, dla IT nie jest czymś całkiem nowym, języki funkcyjne – trochę w historii programowania zdominowane przez języki obiektowe – od dawna byt taki posiadały. Jest wiele definicji Monady:
- filozof powie, że Monada jest substancją prostą, podstawową jednostką
- biolog, że Monada to prosta komórka z jedną wicią (cokolwiek to znaczy) trwale zdolna do poruszania się
- matematyk zaś, że Monada to trójwyrazowy kompleks obiektów pewnej kategorii abelowej (pomijając wyjątki, nikt nie wie o co w tym chodzi 🙂 )
- programista teoretyk powie, że Monada to rodzaj konstruktora abstrakcyjnego typu danych, który implementuje funkcje wiązania (bind) oraz jednostki (unit), tak … to proste 🙂
Nic nam te definicje nie mówią. Jednak od dłuższego czasu mamy Monady w standardowym zestawie klas api Java już od wersji 8 wydanej w 2014 roku. Flagowym przykładem Monady jest Optional. Optional pozwala zamiast takiego kodu:

pisać taki kod:

ale uwaga, na pewno nie taki:
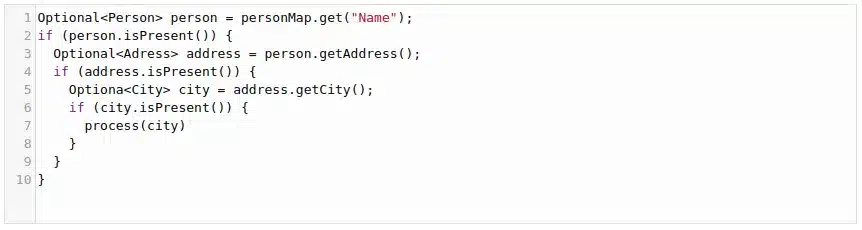
choć nieznający tematu mają ogromną ochotę tak właśnie pisać (tak nie robimy).
Aby zrozumieć sens Monad, odnieśmy się do właśnie do SQL i With. Mając coś na wejściu chcemy poprzez przejście przez klika etapów uzyskać jakieś wyjście. Traktujemy nasze wejście jako jakiś dowolnie złożony strumień danych który będzie ulegał wielokrotnemu przetworzeniu. Przetwarzanie to będzie się odbywało przez sprawdzone, przetestowane i gotowe do użycia elementy. Powodzenie całej operacji zależy tylko od jakości tych elementów i poprawności ich złożenia. Z tym, że złożenie jest wyrazem deklaracji tego jak proces ma wyglądać a nie implementacji. Jak nie ma implementacji, to mamy 1000 razy mniejsze ryzyko pomyłki, tyleż samo więcej szansy na dobrą wydajność. Koszmar NPE już nas nie dotyczy. Chyba, że ktoś z Was dostał kiedyś NPE jako wynik polecenia SQL, chyba jednak nie :). Zobaczcie, że tak użyta Monada w zasadzie jest emanacją prostego zdania „Znajdź osobę o podanej nazwie i jak w jej adresie będzie miasto, to przekaż to miasto do dalszej obsługi”. Bingo.
Największą zaletą Monad jest to, że pozwalają w kodzie osiągać deklaratywność na podobnym poziomie, jaki daje język SQL
To zaledwie drobny fragment zagadnień monadycznych, warto zwrócić uwagę na moc tego bytu, no i oczywiście zachęcam do głębszego zapoznania się z tematem. Dla zainteresowanych polecam bibliotekę vavr (kiedyś Javaslang), która zawiera kilka naprawdę pięknych Monad.
