

























Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Tytułowa postać z greckiej mitologi obdarowana została zdolnością widzenia przyszłości. Jednocześnie nikt nie wierzył jej przepowiedniom. Jej imienniczka „Apache Cassandra”, jeden z wielu dostępnych nierelacyjnych silników baz danych, zdaje się mieć podobną zdolność lecz bez wyżej wspomnianej przypadłości. W momencie pojawienia się w 2008 roku, projekt w pewnym sensie pokazywał, jak w przyszłości mogą wyglądać bazy danych. Odchodząc od paradygmatu relacyjnego, zamieniając język SQL na swój własny CQL, Cassandra wprowadziła nowe zasady przetwarzania i przechowywania danych, często w szokujący sposób sprzeczne z tym co znamy z klasycznych baz relacyjnych. Głównym hasłem Cassandry jest
zapis jest tani,
zapisuj wszystko w taki sposób, w jaki potem chcesz to czytać
Co najmniej dziwne! Jednak jak zazwyczaj, aby zrozumieć powyższe założenia, trzeba przedstawić kontekst. Trzeba zacząć od tego, że Cassandra:
- jest przeznaczona do przechowywania raczej dużych a wręcz ogromnych zbiorów danych, dochodzących nawet do dziesiątek petabajtów,
- gwarantuje wysoką odporność na awarie, dane są przechowywane na wielu maszynach, z lokacją w różnych centrach danych włącznie,
- jest bardzo szybka, głównie ze względu na założenie że ma taka być, co w dużej mierze narzuciło przyjętą architekturę
- nie posiada pojedynczego punktu awarii, nie posiada stałego „master noda”
- jest ogromnie skalowalna, istnieją produkcyjne instalacje składające się z kilkudziesięciu tysięcy serwerów, obsługujące kilka trylionów żądań na dobę, a dodawanie kolejnych maszyn liniowo skaluje zapisy i odczyty
Dodajmy, że dwie główne zasady wpajane od zawsze architektom relacyjnych baz danych, mianowicie:
- jak najmniej zapisów
- unikanie duplikowania danych
nie aplikują się w przypadku Cassandry. Cassandra doskonale radzi sobie z zapisem, można powiedzieć, że zapis ma bardzo niski choć nie pomijalny koszt. Natomiast duplikowanie danych to „chleb powszedni” Cassandry, a zapisz swoje dane wielokrotnie aby potem je szybko czytać, to jedna z podstawowych reguł. Jak to rozumieć? Najprościej jak można, po prostu tworzymy tyle tabel ile jest nam potrzebnych aby do zaspokojenia każdego z zapytań wystarczył odczyt z jednej z nich, a co więcej, z jednej jej partycji. Łatwo to zrozumieć dodając, że CQL nie posiada w swojej składni słowa JOIN, a zapytania dotyczą jednej tabeli. Rozważmy przykład prostej struktury do przechowywania użytkowników i grup do których należą. Dla relacyjnej bazy danych wygląda to tak:
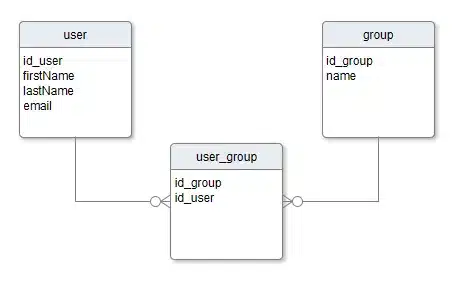
W celu otrzymania listy użytkowników dla grupy o zadanej nazwie potrzebne jest zapytanie SQL:
select u.firstName, u.lastName, u.email
from user u
join user_group ug on (u.id_user = ug.id_user)
join group g on (ug.id_group = g.id_group)
where g.name = ‘nazwa’
Ten sam model dla Cassandry mógłby wyglądać tak:
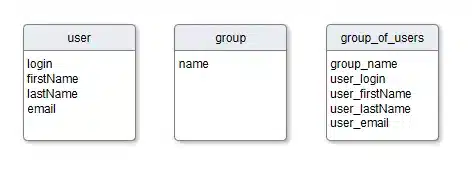
Nie ma w tym modelu relacji. Znikają sztuczne klucze główne. Tabele mają taki kształt ze względu na zapytania które będą na nich operować. Wyszukiwanie użytkownika odbywa się wyłącznie wg pola „login”, wyszukiwanie grupy po „name”, a kiedy chcemy znać listę użytkowników z danej grupy konstruujemy następujące zapytanie CQL:
select user_login, user_firstName, user_lastName,
user_email
from group_of_users
where group_name = ‘nazwa’
Oczywistą konsekwencją powyższego modelu jest konieczność wielokrotnych zapisów np. w przypadku zmiany nazwy grupy, czy nazwiska użytkownika, gdyż dane te znajdują się w wielu wierszach w wielu tabelach. Dla bazy relacyjnej było by to wadą, natomiast dla Cassandry nie jest to problem, a zysk z szybkich odczytów i ogromnej skalowalności jest przeogromny. Czy takie podejście jest lepsze od relacyjnego? Jest inne. Dla wielu zastosowań będzie w oczywisty sposób lepsze, dla wielu innych lepiej sprawdzi się relacyjne. Czyli jest jak zawsze, wszystko zależy od kontekstu wymagań i potrzeb. Apache Cassandra to tylko przykład bazy nierelacyjnej czy nie SQL’owej, rozwiązań tej klasy jest wiele. Aby poszerzyć swoje horyzonty, czy wręcz swój warsztat, warto zapoznać się przynajmniej z architekturą wiodących na rynku rozwiązań, nawet jeżeli wciąż się nam wydaje, że świat SQLem stoi.
